|
I am a machine learning researcher at Qualcomm AI Research, where I work on end-to-end motion planning systems for autonomous driving. Previously, I was a PhD student at Johns Hopkins University, advised by Dr. Vishal Patel. My research spanned 3D object detection with LiDAR, domain adaptation, and vision-language models for 3D visual reasoning.
dhegde1[at]jhu[dot]edu /
CV /
Google Scholar /
Twitter /
Github
|

|
|
|

|
CVPR 2025 Deepti Hegde*, Rajeev Yasarla*, Hong Cai, Shizhong Han, Apratim Bhattacharyya, Shweta Mahajan, Litian Liu, Risheek Garrepalli, Vishal M. Patel, Fatih Porikli arXiv Safe motion planning in autonomous vehicles is crucial, especially in rare and critical "long-tail" scenarios. While recent systems use large language models (LLMs) as planners to improve performance in these situations, they often come with high computational costs at runtime. Our work distills knowledge from multi-modal LLMs to vision-based planners to enable robust open-loop planning while maintaining computational efficiency. |
|
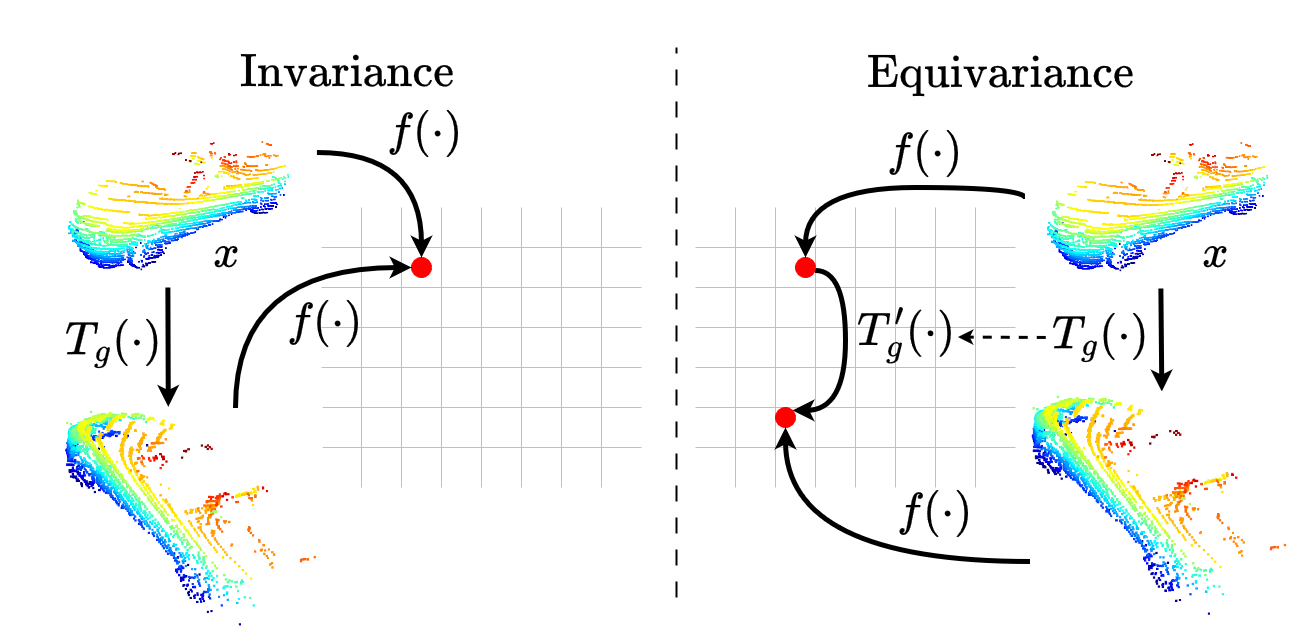
ECCV 2024 Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Mike Jones, Vishal M. Patel arXiv Video We propose a spatio-temporal equivariant learning framework for self supervised pre-training on LiDAR point clouds for the task of 3D object detection. Our experiments show that the best performance arises with a pre-training approach that encourages equivariance to translation, scaling, and flip, rotation and scene flow. For spatial augmentations, we find that depending on the transformation, either a contrastive objective or an equivariance-by-classification objective yields best results. |

|
OpenSun3D @ ICCV 2023 Deepti Hegde*, Jeya Maria Jose Valanarasu* Vishal M. Patel arXiv code CLIP is not suitable for extracting 3D geometric features as it was trained on only images and text by natural language supervision. We work on addressing this limitation and propose a new framework CG3D (CLIP Goes 3D) where a 3D encoder is trained to exhibit zero-shot capabilities. |
|
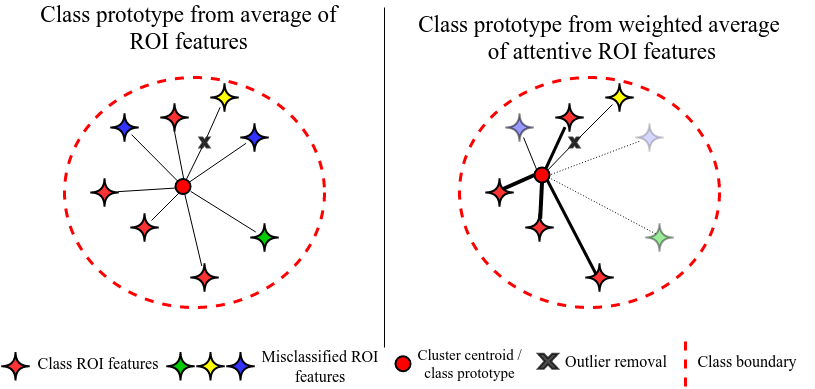
WACV 2024 Deepti Hegde, Vishal M. Patel, arXiv code Addressing the limitations of traditional feature aggregation methods for prototype computation in the presence of noisy labels, we utilize a transformer module to identify outlier ROI's that correspond to incorrect, over-confident annotations, and compute an attentive class prototype. Under an iterative training strategy, the losses associated with noisy pseudo labels are down-weighed and thus refined in the process of self-training. |

|
ICRA 2023 Deepti Hegde, Vishwanath Sindagi, Velat Kilic, A. Brinton Cooper, Mark Foster, Vishal Patel, arXiv In order to avoid reinforcing errors caused by label noise, we propose an uncertainty-aware mean teacher framework which implicitly filters incorrect pseudo-labels during training. Leveraging model uncertainty allows the mean teacher network to perform implicit filtering by down-weighing losses corresponding uncertain pseudo-labels. |

|
Velat Kilic, Deepti Hegde, Vishwanath Sindagi, A. Brinton Cooper, Mark Foster, Vishal Patel, arXiv code We propose a physics-based approach to simulate lidar point clouds of scenes in adverse weather conditions. These augmented datasets can then be used to train lidar-based detectors to improve their all-weather reliability. Specifically, we introduce a hybrid Monte-Carlo based approach that treats (i) the effects of large particles by placing them randomly and comparing their back reflected power against the target, and (ii) attenuation effects on average through calculation of scattering efficiencies from the Mie theory and particle size distributions. |